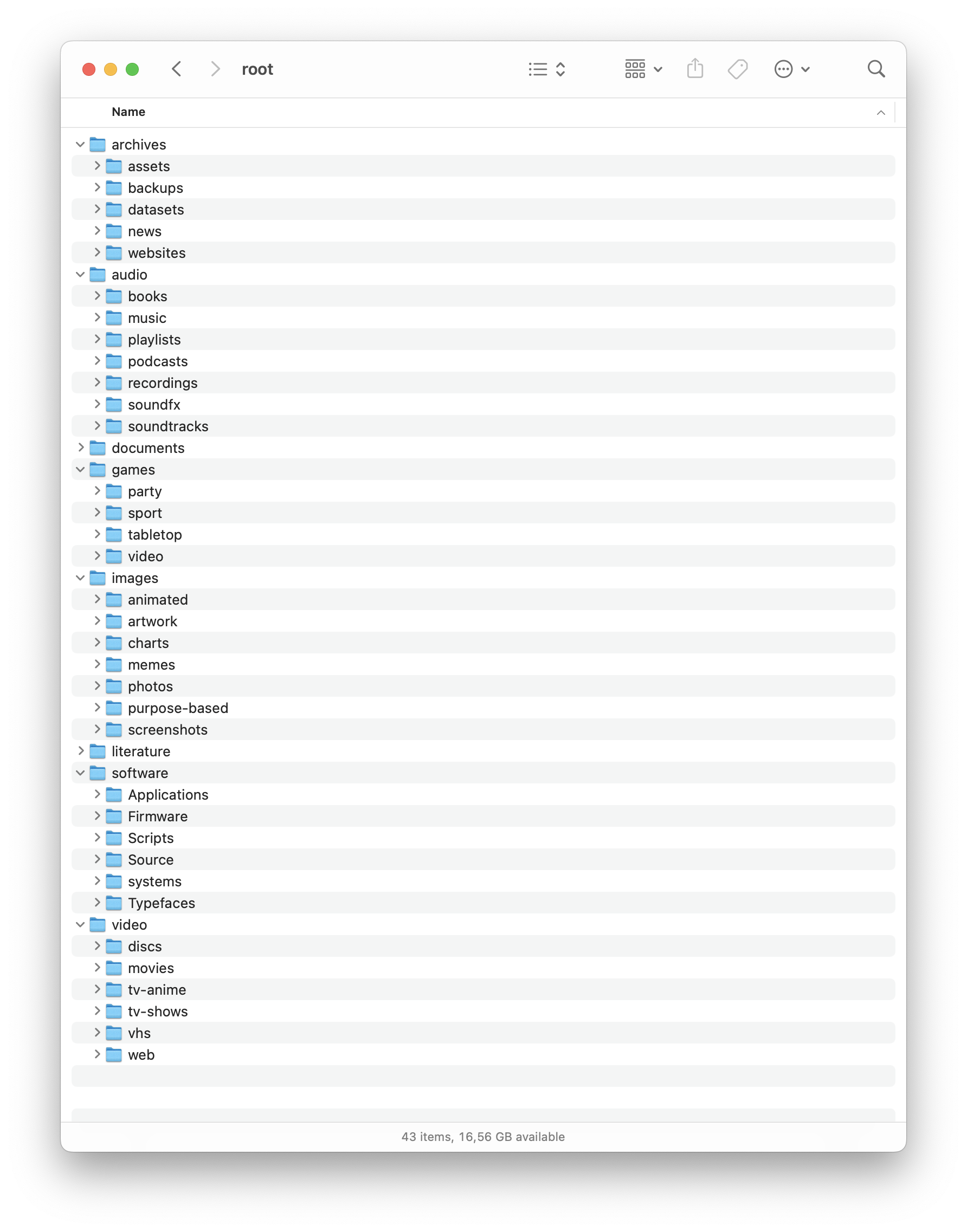
DataCurator-Filetree is a small GitHub project (1.6k stars, MIT-licensed) created by roboyoshi and the /r/datacurator community. In one repo it ships a ready-made directory tree so people who archive music, movies, documents, source code, etc. can start from the same naming scheme instead of reinventing their own. The README states the goal plainly: “create a unified filetree for all kinds of data, which should help in storing, categorising and retrieving.”
This template is mostly for digital-archivist types—people who back up “everything” and want predictable places to drop files. A pared-down plex branch is offered for home-media-server users, while other variants (scene, home) cover specific use-cases.
Tools mentioned
- Plex Media Server – the repo keeps a special
plex/branch containing only the folders Plex libraries care about.
Steps to follow
- Pick the branch that matches your needs:
default,plex,scene, orhome. - Clone or download the repo and copy the folder hierarchy onto your storage volume.
- Leave the
.gitkeepplaceholders (or delete them later) and start moving files into their matching subfolders. - If a common category is missing, open an issue or PR so the community can discuss adding it.
Advice
- Keep everything under one top-level tree (
root/in the screenshot) so backup jobs are simple. - Use the provided names verbatim—e.g.
archives/,audio/,images/,software/,video/. Sub-folders already cover common cases (audio/music,images/photos,video/movies, etc.). - Avoid duplicating folder concepts; if you’re unsure where something belongs, the maintainers suggest opening an issue rather than creating ad-hoc folders.
See the original GitHub repository for the full tree and README, plus any ongoing discussions or updates (initial release v0.2 — Apr 12 2019). https://github.com/roboyoshi/datacurator-filetree
Conclusion
I’m not going to dig into every single subfolder layout here—the branch-specific details (like deciding between video/movies and video/tv_shows) get hyper-granular and drift away from my focus. The point of these notes is just to log that DataCurator-Filetree exists, outline its main categories, and capture how its high-level scheme might inspire our own photo-centric method—anything deeper feels out of scope for this blog series.